


Detektion von Toxizität und Aggressionen in Postings und Kommentaren im Netz
DeTox :: Detektion von Toxizität und Aggressionen in Postings und Kommentaren im Netz
Das Forschungsprojekt DeTox befasst sich mit der automatischen Erkennung von Toxizität und Aggressionen in Postings und Kommentaren im Netz. Motto: Hass ist Gift!
Zusammen mit der Meldestelle Hasskommentare des Hessen3C sollen automatische Erkennungs- und Klassifikationsverfahren zu „Fake News“ und „Hate Speech“ entwickelt werden. Eine genauere Angabe, was unter „Hate Speech“ verstanden wird, ist unter Projekt zu finden.
Wichtig ist nicht nur die Erkennung und Klassifizierung von Beiträgen als „Hate Speech“, sondern auch wie etwas erkannt, gemeldet und bewertet wird. Die Frage nach der Toxizität und Aggressivität ist für präventive Maßnahmen von großer Bedeutung.
Ein wichtiger Punkt ist weiterhin die Erklärbarkeit der Klassifikationsergebnisse, da diese gerade in Bezug auf „Fake News“ und „Hate Speech“ begründbar sein müssen.
Das Ziel einer neuartigen und nachhaltigen Strategie für eine automatisierte Detektion von Toxizität und Aggressionen in Postings und Kommentaren im Netz kann nur in einem Verbund aus Wissenschaft und Anwendern umgesetzt werden.



Das Projekt DeTox
Das Forschungsvorhaben betrifft den Förderbereich “Erforschung und Entwicklung automatisierter Erkennungs- und Klassifikationsverfahren von ‘Fake News’ und ‘Hate Speech’ in Zusammenarbeit mit der Meldestelle Hasskommentare des Hessen3C”. In diesem Projekt soll ein deutlicher Bezug zu „Hate Speech“ hergestellt werden.
Hassrede ist durch „gruppenbezogene Menschenfeindlichkeit“ gekennzeichnet
‘Hate Speech’ umfasst das weite Spektrum von dem Gebrauch von Schimpfwörtern über Beleidigungen und Diskriminierungen bis hin zu Gewaltandrohungen (Ruppenhofer et al. 2018). Wir verwenden den Begriff ‘Hate Speech’ stellvertretend für die Vielzahl möglicher offensiver Inhalte. Es ist zu beachten, dass der Begriff Hate Speech, Hasskommentar bzw. Hassrede nicht legal definiert ist. Als Grundlage kann die Begriffserklärung der zentralen Meldestelle „Hasskommentare“ des Hessen3C dienen: Postings, Kommentare und Bilder, die Menschen aufgrund ihrer zugeschriebenen oder tatsächlichen Nationalität, ihrer ethnischen Zugehörigkeit, Hautfarbe, Religionszugehörigkeit, Weltanschauung, physischen und/oder psychischen Behinderung oder Beeinträchtigung, ihres Geschlechts, der sexuellen Orientierung und/oder sexuellen Identität, ihrer politischen Haltung, Einstellung und/oder Engagements, ihres äußeren Erscheinungsbildes oder sozialen Status angreifen, entsprechende Äußerungen fördern, rechtfertigen oder dazu anstiften. Hassrede ist demnach durch seine „gruppenbezogene Menschenfeindlichkeit“ gekennzeichnet.
Identifizierung und Bewertung notwendig
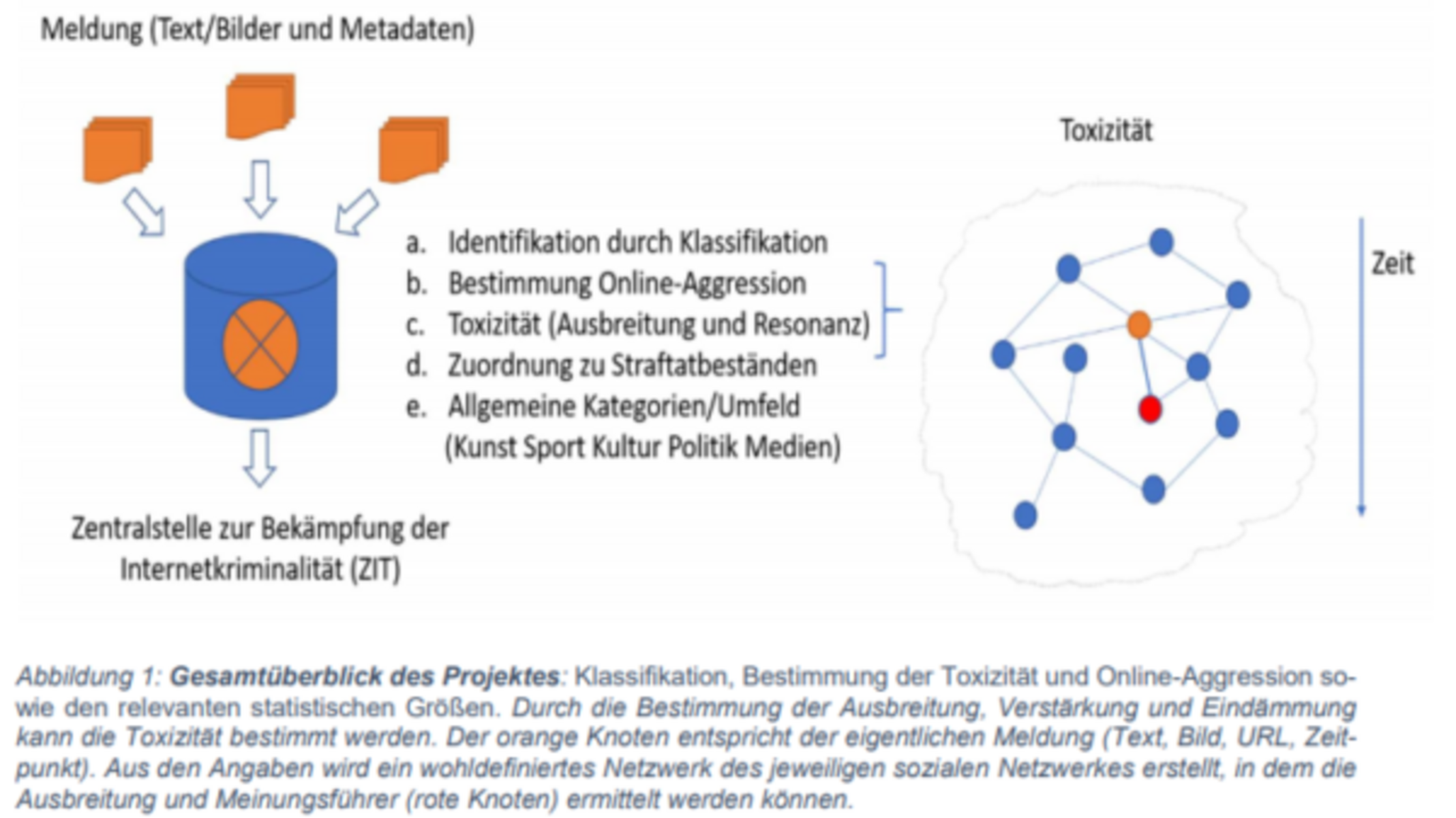
Die sozialen Medien wie Twitter, Facebook und auch die Kommentarspalten der Online-Präsenzen von Zeitungen und Radiosendern werden zunehmend von Menschen dominiert, die diffamieren, beleidigen und bedrohen. Automatisch generierte Nachrichten werden verwendet, um den Eindruck zu erwecken, dass diese extremen Meinungen in der Bevölkerung weit verbreitet sind, aber auch, um politische Gegner mundtot zu machen. Infolgedessen gelingt es vielen Betreibern von Social-Media-Webseiten nicht mehr, Nutzerbeiträge manuell zu moderieren, und es bedeutet für die Moderatoren eine enorme psychische Belastung. Daher besteht ein dringender Bedarf an Methoden zur automatischen Identifizierung verdächtiger Beiträge. Neben der Identifizierung bedarf es einer normativen und moralisch-gesellschaftlichen Bewertung.
Das Gesamtziel des Projekts ist die Detektion, Identifizierung und Bewertung von Hasskommentaren. Die Bewertung soll auf zwei Ebenen erfolgen: Toxizität und Aggression.
Neben der Identifizierung im Sinne der Klassifizierung von Beiträgen mit ‘Hate Speech’-Inhalten soll es auch um den Prozess der Detektion, Meldung und der Bewertung gehen. Die Frage nach der Toxizität und Aggressivität ist für präventive Maßnahmen von großer Bedeutung.
Es gibt noch keine optimale Verfahren
Die KI stellt Methoden zur automatischen Textklassifikation zur Verfügung, die auf diese Aufgabe angewendet werden sollen. Im Zusammenhang mit der Organisation des Forschungswettbewerbs GermEval haben wir Erfahrungen mit der automatischen Klassifikation von aggressiven Äußerungen in Social-Media-Daten sammeln können. Ca. 25 internationale Forschungsgruppen haben ihre Methoden miteinander verglichen und kombiniert. Dennoch war das Fazit: “All in all, these results underline that the problem of offensive language detection is far from solved” (Struß et al. 2019). Dieses Fazit gilt insbesondere für die deutsche Sprache, die im Projekt (wie bei der GermEval) im Vordergrund stehen soll. Wir werden an die Ergebnisse anknüpfen und Verfahren wie Transformer-Modelle (z. B. Risch et al. 2019) mit Support Vector Machines (z. B. Montani und Schüller 2018) verknüpfen, um die Ergebnisse zu optimieren. Vorgesehen sind Klassifikationsexperimente, um optimale Kombinationen von Verfahren zu erreichen.
Dabei behalten wir die Erklärbarkeit der Klassifikationsergebnisse im Auge, denn besonders bei Verfahren, die mit neuronalen Netzen arbeiten, ist zunächst nicht ersichtlich, wie die Klassifikationen zustande kommen. Besonders beim Thema ‘Fake News’, aber auch bei ‘Hate Speech’ besteht aber die dringende Notwendigkeit, Klassifikationen zu begründen. In Zusammenarbeit mit der Meldestelle Hasskommentare des Hessen3C werden wir ein annotiertes (vorklassifiziertes) Textkorpus aufstellen, das als Grundlage für die Experimente und für die Evaluationen dienen wird. Das annotierte Textkorpus unterliegt einem ständigen Wandel. Möglicherweise können verifiziert gemeldete Nachrichten oder Profile für eine Art Feedbacksystem genutzt werden. Im Sinne eines Active-Learning-Ansatzes (S.-A. Ahmadi, 2017) kann so die ständige Weiterentwicklung und Adaption des Klassifikators an sich verändernde Sprachgewohnheiten und Themen garantiert werden.
Opinion Leader können großen Einfluss haben
Die Toxizität und Aggressivität können aus den verifizierten Meldungen ermittelt werden. Hierbei wird die Wirkung anhand der Ausbreitung, Verstärkung und Eindämmung in einem abgegrenzten Netzwerk gemessen. Wenn eine Diskussion thematisch mit Hate Speech in Verbindung gebracht wurde, könnte die Messung der Emotionsänderung im Netzwerk (positivenegative) gemeinsam mit dem zeitlichen Wachstum des Netzwerks einen starken Hinweis auf die Aufnahme und Verbreitung des Gedankengutes liefern. Dieser Effekt wird verstärkt, wenn selektive Anreize vorhanden und wenn Aggressoren intrinsisch motiviert sind. Darüber hinaus sind möglicherweise Rückschlüsse auf Übersprungshandlungen in die reale Welt feststellbar. Maße, wie der durch FoSIL entwickelte Competence Rank können dann dazu beitragen geeignete Adressaten für Interventionen zu ermitteln.
Dabei können Opinion Leader, im Deutschen auch Meinungsführer, also Personen, die innerhalb einer kleineren Gruppe kommunikativ und persönlich einen hohen Einfluss auf die anderen Gruppenmitglieder haben, über den Competence Rank (z. B. M. Spranger, et al.2018) gemessen werden. Die Messung erfolgt auf der Grundlade der „Sozialen-Norm-Theorie“ und wird mittels der Sentimentanalyse (Siegel & Alexa 2020) durchgeführt. Für die Definition des erforderlichen Sentiment-Wortschatzes soll das Wissen der Hessen3C generisch aufbereitet werden. Somit besteht die Chance, nicht nur den eigentlichen Verfasser zu monitoren, sondern zu prüfen, ob und in welche Richtung sich der jeweilige Hasskommentar entwickelt hat.
Crowd-Labeling-Ansatz bei Annotation
Mit Hilfe des von FoSIL entwickelten Annotationswerkzeugs können umfangreiche annotierte Korpora auf Basis eines Crowd-Labeling-Ansatzes erzeugt werden, welche die Grundlage für die Erzeugung eines Goldstandards bilden. Den dabei zu berücksichtigenden Unsicherheiten bezüglich der Vertrauenswürdigkeit der einzelnen Annotatoren kann mittels des ebenfalls durch FoSIL entwickelten Inter-Rater-Agreement-Learning-Ansatzes (IRAL) begegnet werden (J. Cohen, 1960; K.-J. Hanke, et al. 2020). Dieser Ansatz ermöglicht die Steuerung des Einflusses jedes einzelnen Annotators auf das Gesamtergebnis mit Hilfe eines individuellen Profilings.
Syntaktische Auffälligkeiten sollen ebenfalls in die Lernprozesse einbezogen werden, bzw. können dadurch detektiert werden. Wenn das “Verfassen” von Hate Speech oder Fake News durch Social Bots in Betracht gezogen wird, erhöht sich die Wahrscheinlichkeit der Detektion.
Zum Nachweis eines derartigen Phänomens würden aber Nachrichten benötigt, die nachweislich von Social Bots stammen. Ein erfolgversprechender Ansatz liegt in der lexikalischen Analyse in Zusammenhang mit Word Embeddings, die bestimmte wiederkehrende rhetorische Begriffe und Phrasen entdeckt, die symptomatisch für diese Art von Texten sind.
Das Ziel einer neuartigen und nachhaltigen Strategie für eine automatisierte Detektion von Toxizität und Aggressionen in Postings und Kommentaren im Netz kann nur in einem Verbund aus Wissenschaft und Anwendern umgesetzt werden.
Der vorgestellte Ansatz dient nicht nur der eigentlichen Detektion und Klassifikation, sondern beschäftigt sich auch mit der Ausbreitung und der Überführung in einzelne Straftatbestände.
News
Partner
Hochschule Darmstadt
Melanie Siegel ist seit 2012 Professorin für Informationswissenschaft – insbesondere semantische Technologien an der Hochschule Darmstadt. Sie hat 1996 an der Universität Bielefeld in Linguistik promoviert und 2007 mit einer Venia für Computerlinguistik und Sprachtechnologie habilitiert. Sie hat von 1995 bis 2006 am Deutschen Forschungszentrum für Künstliche Intelligenz (DFKI) und der Universität Saarbrücken zu Themen der Sprachtechnologie geforscht. 2006 bis 2012 arbeitete sie als Computerlinguistin in einer Software-Firma. 2018 und 2019 hat sie gemeinsam mit Wissenschaftlern aus Saarbrücken, Heidelberg, Mannheim, Potsdam und Zürich die „GermEval Shared Task on the Identification of Offensive Language“ organisiert. Siegel ist Mitglied im Forschungszentrum für angewandte Informatik der Hochschule Darmstadt und im Promotionsausschuss des Promotionszentrums für angewandte Informatik der hessischen Hochschulen.
Jonas Pitz ist Student im Master Studiengang Information Science mit besonderem Fokus auf Semantic Web und Natural Language Processing an der Hochschule Darmstadt. 2015 war er als Mitarbeiter beteiligt an der Entwicklung eines digitalen Archivs für die Pina Bausch Stiftung in Wuppertal. 2019 arbeitete er als Datenmodellierer an dem Digitalisierungsprojekt „Nonverbales Theater im ehemaligen Ostteil Berlins 1970-1991“ des Internationalen Theaterinstituts in Berlin.
Nadine Probol ist Studentin an der Hochschule Darmstadt im Master Information Science. 2019 hat sie ihr Bachelorstudium mit einer Arbeit zu Mensch-Maschine-Interaktionen im Recruiting-Prozess anhand von Chatbots abgeschlossen. Ihr besonderer Fokus liegt auf der automatischen Erkennung von Emotionen und der Sentimentanalyse mithilfe von Machine-Learning- und Deep-Learning-Verfahren. 2020 arbeitete sie an einem Forschungsprojekt zur Produktion von digitalen Lehr- und Lernangeboten für Abschlussarbeiten mit.
Mina Schütz hat im Mai 2020 ihren Masterabschluss im Fach Informationswissenschaft an der Hochschule Darmstadt absolviert und ist dort seit Ende 2020 Doktorandin am Promotionszentrum für angewandte Informatik. Zudem arbeitet sie seit 2019 beim AIT Austrian Institute of Technology GmbH in Wien im Center Digital Safety and Security im Bereich Data Science & Artificial Intelligence. Sie hat sich seit dem Master vor allem auf Natural Language Processing und Machine Learning mit Fokus auf Desinformation spezialisiert und ihre Master-Arbeit über die automatische Erkennung von Fake News mit Transformer-Modellen verfasst. Weitere Forschungsschwerpunkte sind Information Retrieval, Semantic Web, Text-Analyse und Deep Learning, insbesondere multi-linguale und transfer learning Methoden mit Sprachenmodellen. Ein weiterer Fokus sind hierbei auch Methoden zur Erklärbarkeit von Machine Learning Modellen (Explainable Artificial Intelligence).
Fraunhofer SIT / Hochschule Mittweida
Dirk Labudde ist seit 2017 Leiter des Lernlabors Cybersicherheit der Fraunhofer Academy und Gruppenleiter am SIT Darmstadt. Seit 2009 hat er eine Professur für Bioinformatik und seit 2014 für Allgemeine und Digitale Forensik an der Hochschule Mittweida und leitet dort auch die Forschungsgruppe FoSIL, welche sich mit den verschiedensten forensischen Fragestellungen aktuellen Themen aus der sicherheitsrelevanten Forschung beschäftigt und in dessen Rahmen viele Vorarbeiten zum beantragten Projekt entstanden sind. Der Kern liegt in der Identifikation von aus forensischer- bzw. Sicherheitssicht relevanten, innovativen Technologien und deren Verbindung mit agilem Wissensmanagement zu Werkzeugen für die Forensische Praxis bzw. den Einsatz im interdisziplinären Management im Krisen- und Katastropheneinsatz. Einer der Forschungsschwerpunkte ist die semantische Analyse von forensischen Texten und Bildern/Videos. Die entwickelten Softwareplattformen MoNA und SoNA werden heute in den verschiedensten Behörden der Länder und des Bundes eingesetzt. Dirk Labudde hat 1997 in Theoretischer Physik an der Universität Rostock promoviert. Er erhielt 2014 den sächsischen Lehrpreis und wurde 2018 Fellow der IARIA.
Christoph Demus ist Student an der Hochschule Mittweida im Master Cybercrime/Cybersecurity und seit Anfang 2021 wissenschaftlicher Mitarbeiter am Fraunhofer SIT Darmstadt. 2020 hat er das Bachelorstudium der Allgemeinen und Digitalen Forensik mit einer Arbeit zum Thema Named Entity Recognition abgeschlossen. Zusammen mit der Forschungsgruppe FoSIL hat er 2019 erfolgreich am „GermEval Shared Task on Hierarchical Classification of Blurbs“ teilgenommen.
Gefördert durch die „Forschungsförderung Cybersicherheit“ des Referats „Innovationsmanagement Cybersicherheit“ des Hessischen Ministeriums des Innern und für Sport
Publikationen
- Postersession der Sektion Computerlinguistik auf der 44. Jahrestagung der Deutschen Gesellschaft für Sprachwissenschaft
- Mina Schütz, Alexander Schindler, Melanie Siegel (2021). Disinformation Detection: An
Explainable Transfer Learning Approach. In CODE Conference 2021 – Science Workshop for
Ph.D. and masters’ theses research proposals. - Schütz, Mina and Demus, Christoph and Pitz, Jonas and Probol, Nadine and Siegel, Melanie
and Labudde, Dirk: DeTox at GermEval 2021: Toxic Comment Classification. In Proceedings
of GermEval 2021. - Demus, Christoph and Pitz, Jonas and Schütz, Mina and Probol, Nadine and Siegel, Melanie
and Labudde, Dirk. 2022. DeTox: A Comprehensive Dataset for German Offensive Language
and Conversation Analysis. In Proceedings of the Sixth Workshop on Online Abuse and Harms
(WOAH), pages 143–153, Seattle, Washington (Hybrid). Association for Computational
Linguistics. - Köhler, J., Shahi, G.K., Struß, J.M., Wiegand, M., Siegel, M., Mandl, T., Schütz, M.: Overview
of the CLEF-2022 CheckThat! lab task 3 on fake news detection. In: Working Notes of CLEF
2022—Conference and Labs of the Evaluation Forum. CLEF ’2022, Bologna, Italy (2022). - Christoph Demus and Mina Schütz and Jonas Pitz and Nadine Probol and Melanie Siegel and
Dirk Labudde. 2022. Hass im Netz – Aggressivität und Toxizität von Hasskommentaren und
Postings, Detektion und Analyse. In: Handbuch Cyberkriminologie, hrsg. von Thomas-Gabriel
Rüdiger und Petra Saskia Bayerl. Springer. - Christoph Demus, Dirk Labudde, Jonas Pitz, Nadine Probol, Mina Schütz, Melanie Siegel.
2022. Automatische Klassifikation offensiver deutscher Sprache in sozialen Netzwerken. In:
Digitale Hate Speech, hrsg. von Sylvia Jaki und Stefan Steiger. Springer. (to appear)
Fachvorträge:
Mina Schütz, Alexander Schindler, Melanie Siegel (2021). Disinformation Detection: An
Explainable Transfer Learning Approach. In CODE Conference 2021 – Science
Workshop for Ph.D. and masters’ theses research proposals.
www.unibw.de/code/events/code2021_content/code-2021-cfp-science-track
Eingeladener Vortrag auf der Online-Tagung: Interdisziplinäre Perspektiven auf Hate Speech
und ihre Erkennung (IPHSE) (8.2.2021) (Melanie Siegel)
Eingeladener Vortrag auf der Konferenz "Qurator 2021 – Conference on Digital Curation
Technologies" (10.2.2021) (Melanie Siegel)
Eingeladener Vortrag bei der Digitalstadt Darmstadt (20.4.21) (Melanie Siegel)
Eingeladener Vortrag bei „Hessenmetall Verband der Metall- und Elektro-Unternehmen
Hessen e.V.“: "Hass und Hetze im Netz" (15.6.2021) (Melanie Siegel)
Ringvorlesung „Cybercrime: Wie Künstliche Intelligenz uns täuschen kann“ (Dirk Labudde)
Jonas Pitz: Vortrag zum Projekt beim Science Wednesday der Hochschule Darmstadt
(17.11.2021).
Melanie Siegel: Vortrag zum Projekt beim Forschungszentrum für Angewandte Informatik
(18.11.2021)
Die Teilnahme von Jonas Pitz an der Poster-Session der Deutschen Gesellschaft für
Sprachwissenschaften (DGfS) 2022.
Online-Vortrag von M. Siegel für die Gesellschaft für Informatik am 22.3.2022.
Vortrag beim Forensik-Abend der Hochschule Mittweida: Der Einsatz von Sprachtechnologie
gegen Online-Hetze
Vortrag beim ECT Lab Online-Seminar “Just digital futures”: DeTox – Detection of toxicity and
aggression in postings and comments on the internet
Vortrag beim Datenjournalistentreffen der ARD in Frankfurt: Impuls: Was man mit dem
Computer aus Texten alles herauslesen kann - und was nicht
